【ML】机器学习概述与简单应用
什么是机器学习
直观视角下的机器学习
大众视角:

程序员视角:
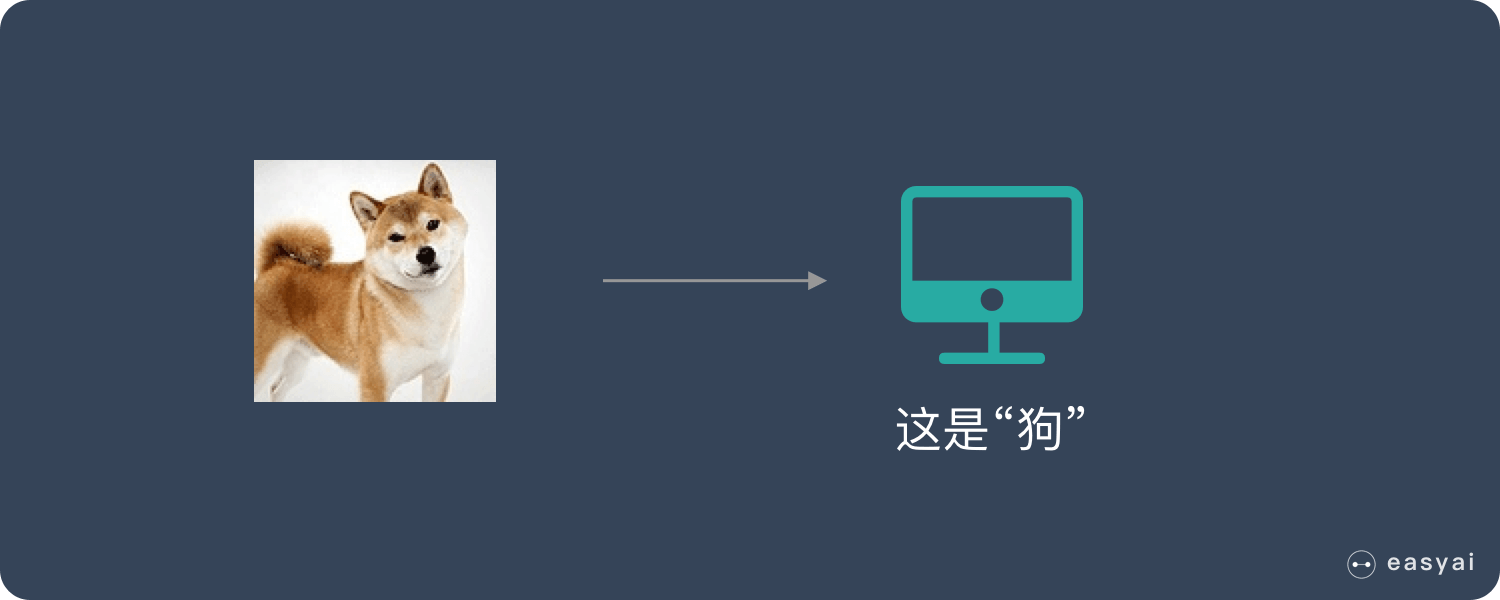
目前机器学习已经应用到了生活的各个方面。
百度搜索:其背后有这复杂的机器学习系统在努力地进行这个跟我们目标关键词相关的检索、排序工作;
美图、美拍这样的照相软件:使用了机器学习来识别面部并进行一定程度的美化;
垃圾箱里躺着的垃圾邮件:它们都不是我们主动拖拽移动进去的,而是机器学习帮我们自动地识别了垃圾邮件;
京东、天猫购物时,推荐的一些我们感兴趣的商品:促成我们更加便捷地购买,机器学习的推荐算法在其中发挥作用;
还有,新闻的推荐系统、语音识别、自然语言处理、无人驾驶、机器翻译等众多领域都有机器学习的影子。
维基百科:https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0
百度百科:https://baike.baidu.com/item/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/217599
机器学习实际上是一门”教会”计算机学习而不需要明确地进行编程的科学。比如,扫地机器人,它应该怎样帮助我们清扫我们的房子呢?一种办法是让它学习我们如何清扫,让它看看我们都捡起了什么东西,然后把它们又放到什么地方,而不需要编写固定的程序让它们识别垃圾,并将它们移动到固定的垃圾桶。
机器学习——实际上在很多问题上都是一种通用解决方案。
它只需要通过大量的实例就可以以很高的精度逼近准确的解决方案。它带来的好处是不需要严格地去分析具体问题并构造精确解,它以一种通用的解决方案框架来对问题进行抽象建模,并通过大量的实例来纠正模型中的参数,并最终以该模型来逼近精确解,最终达到应用标准。
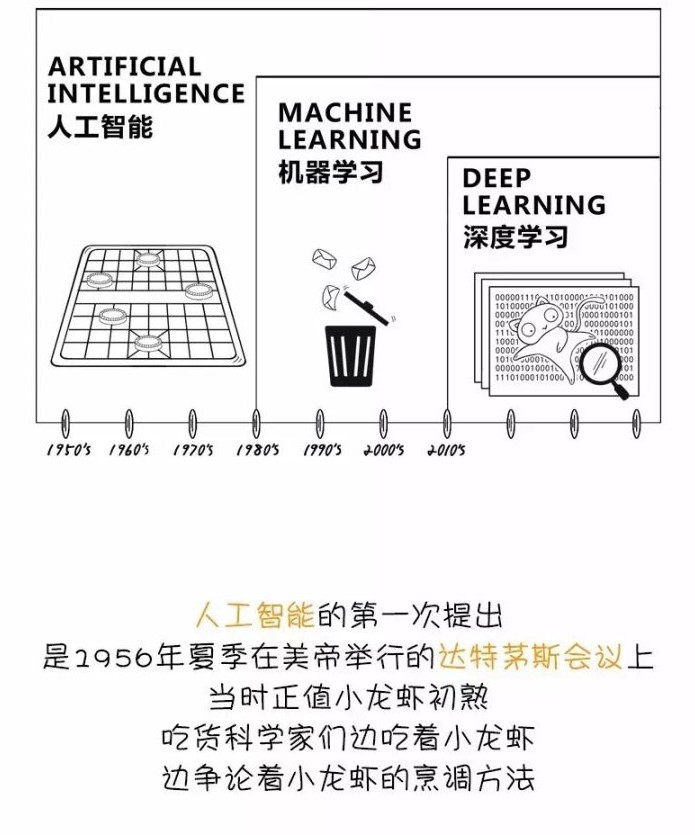
人工智能、机器学习与深度学习


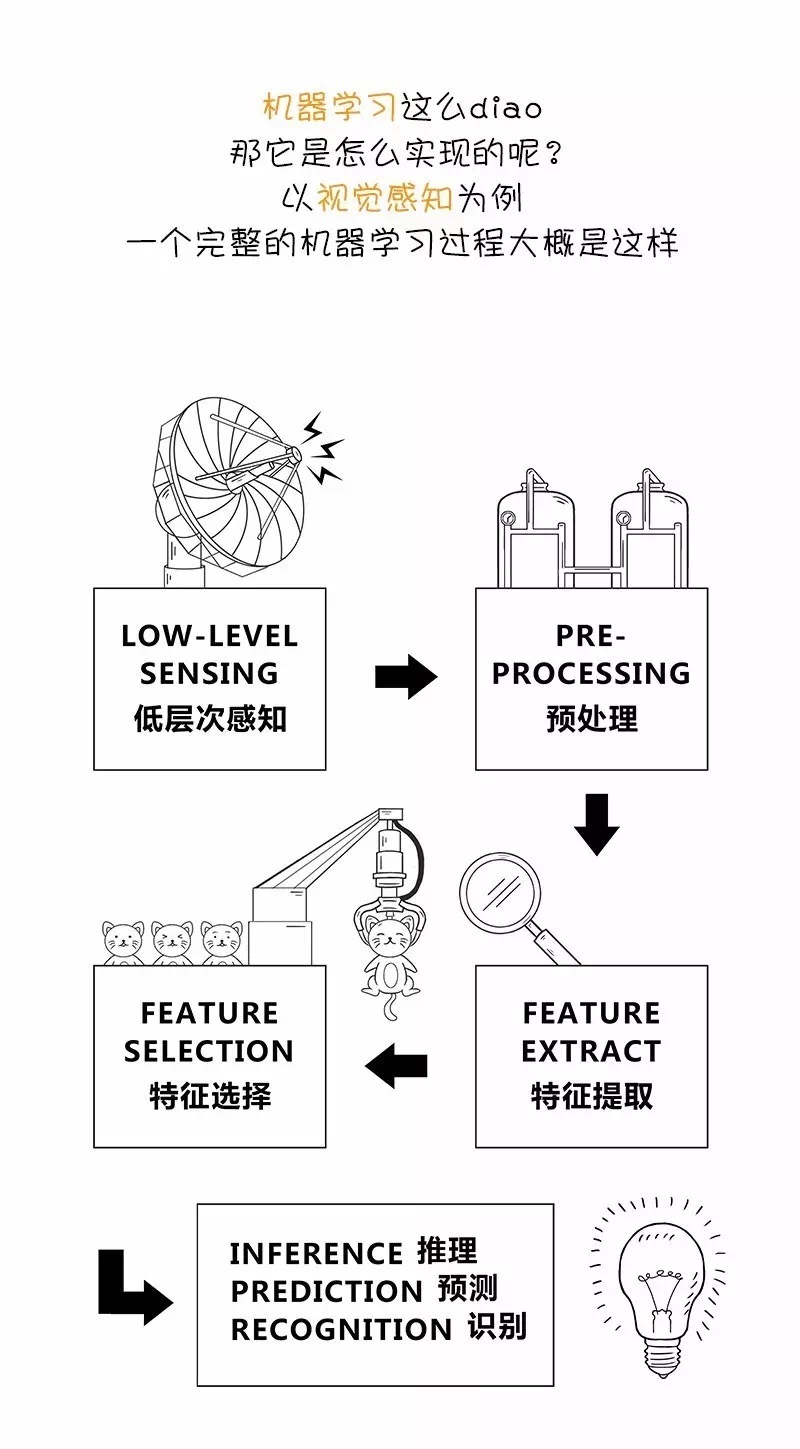

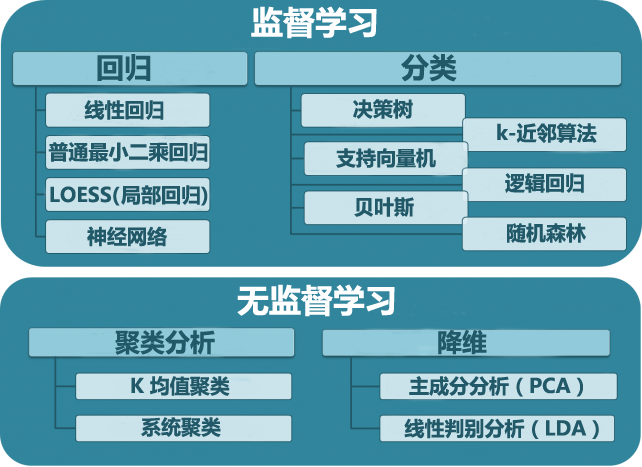
机器学习分类
机器学习根据训练方法大致可以分为3大类:
- 监督学习
- 非监督学习
- 强化学习
除此之外,大家可能还听过“半监督学习”之类的说法,但是那些都是基于上面3类的变种,本质没有改变。
监督学习
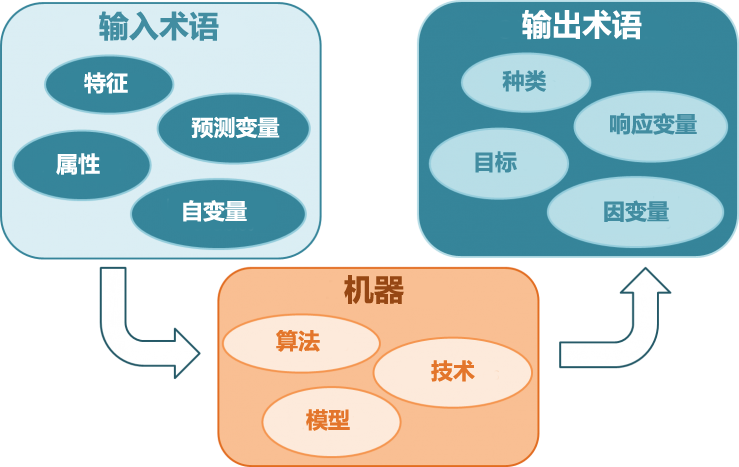
监督学习是指我们给算法一个数据集,并且给定正确答案。机器通过数据来学习正确答案的计算方法。
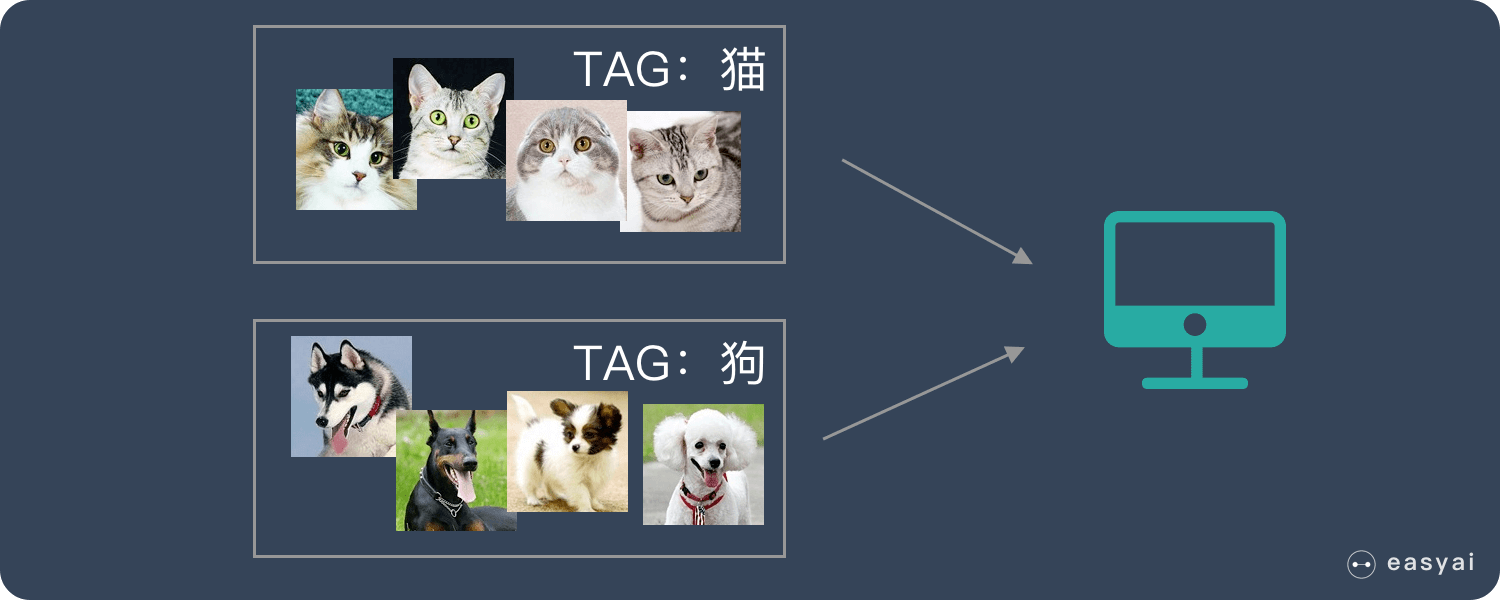
监督式学习采用分类和回归技术开发预测模型。
分类技术可预测离散的响应 — 例如,电子邮件是不是垃圾邮件,肿瘤是恶性还是良性的。分类模型可将输入数据划分成不同类别。典型的应用包括医学成像、语音识别和信用评估。
如果您的数据能进行标记、分类或分为特定的组或类,则使用分类。例如,笔迹识别的应用程序使用分类来识别字母和数字。在图像处理和计算机视觉中,无监督模式识别技术用于对象检测和图像分割。
回归技术可预测连续的响应 — 例如,温度的变化或电力需求中的波动。典型的应用包括电力系统负荷预测和算法交易。
如果您在处理一个数据范围,或您的响应性质是一个实数(比如温度,或一件设备发生故障前的运行时间),则使用回归方法。
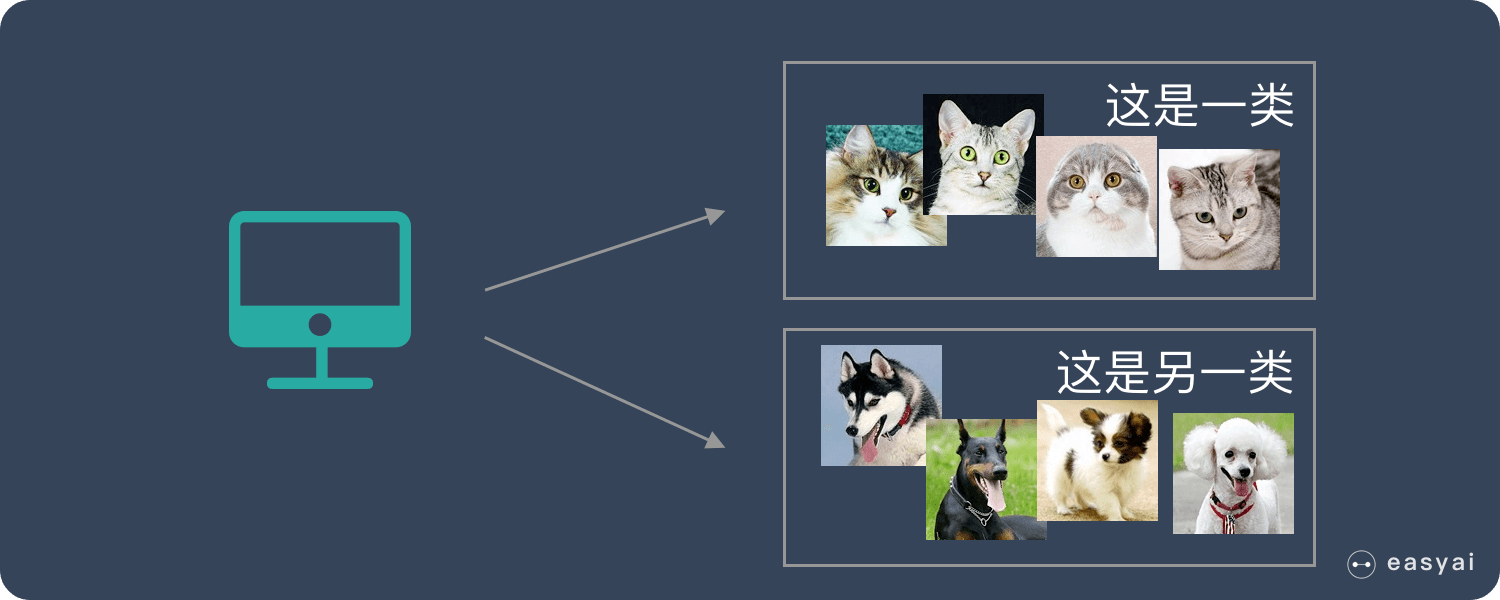
非监督学习
非监督学习中,给定的数据集没有“正确答案”,所有的数据都是一样的。无监督学习的任务是从给定的数据集中,挖掘出潜在的结构。

聚类是一种最常用的无监督学习技术。这种技术可通过探索性数据分析发现数据中隐藏的模式或分组。聚类分析的应用包括基因序列分析、市场调查和对象识别。
降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中。降维的本质是学习一个映射函数 f : x->y,其中x是原始数据点的表达,目前最多使用向量表达形式。
目前大部分降维算法处理向量表达的数据,也有一些降维算法处理高阶张量表达的数据。之所以使用降维后的数据表示是因为在原始的高维空间中,包含有冗余信息以及噪音信息,在实际应用例如图像识别中造成了误差,降低了准确率;而通过降维,我们希望减少 冗余信息 所造成的误差,提高识别(或其他应用)的精度。又或者希望通过降维算法来寻找数据内部的本质结构特征。
强化学习
强化学习更接近生物学习的本质,因此有望获得更高的智能。它关注的是智能体如何在环境中采取一系列行为,从而获得最大的累积回报。通过强化学习,一个智能体应该知道在什么状态下应该采取什么行为。
怎样由数据和答案得到规则?
数据收集
公司历史数据积累
常见公开数据集
https://www.infoq.cn/article/zCGdpvyxJJl7*ja4RQAZ
https://zhuanlan.zhihu.com/p/34497496
网络爬虫
特征表达(去噪、特征提取与选择)
其实,说白了,就是我们人眼可见的特征转化为数字特征(可以用数学公式)的过程,并且这一过程是机器学习最重要的环节。
去噪:去除影响机器学习结果的原始数据。
分类变量特征提取:房价预测中房子的面积、朝向、位置、装修、楼层等等,它是标记的变量,不是连续的。
文字特征提取:很多机器学习问题涉及自然语言处理(NLP),必然要处理文字信息。文字必须转换成可以量化的特征向量。例如咱们公司的研发部算法组做的垃圾广告屏蔽器。
图片特征提取:做图像识别时,我们人眼看到的时图片,但是在机器中则是一个数字表示的二维矩阵。
数据标准化:主要用于对提取后的数字特征进行处理,因为提取好的数字特征可能会差距比较大,那么训练模型时,得到的特征权重会比较大或者比较小,同时也影响计算速度。
模型选择
选择正确的算法看似难以驾驭——需要从几十种监督式和非监督机器学习算法中选择,每种算法又包含不同的学习方法。
没有最佳方法或万全之策。找到正确的算法只是试错过程的一部分——即使是经验丰富的数据科学家,也无法说出某种算法是否无需试错即可使用。但算法的选择还取决于您要处理的数据的大小和类型、您要从数据中获得的洞察力以及如何运用这些洞察力。
模型训练
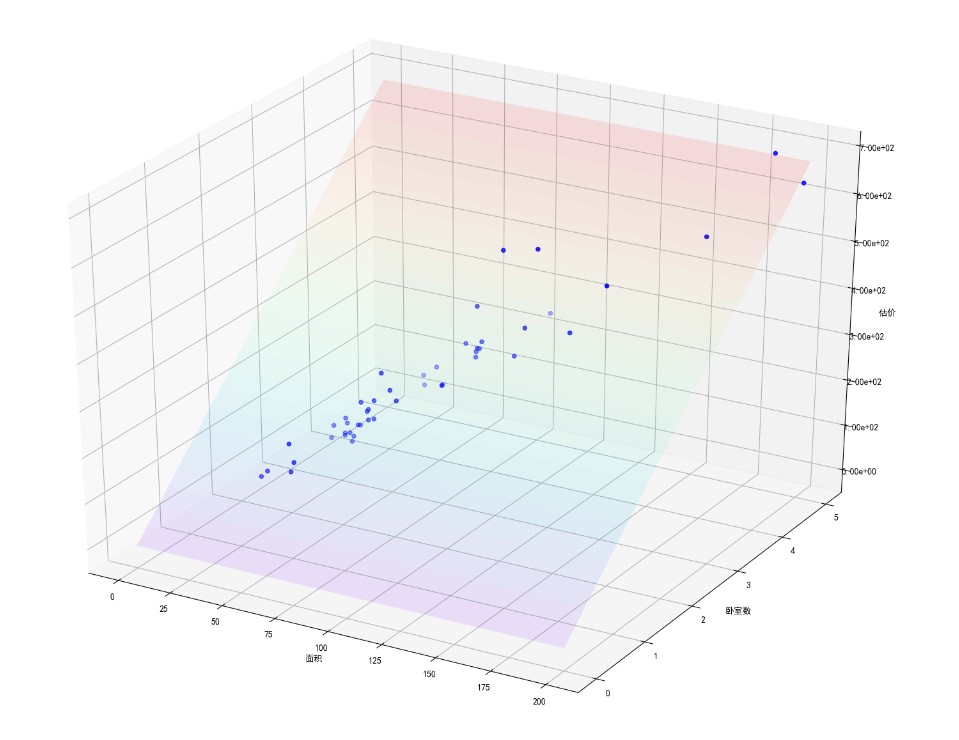
房价预测为例
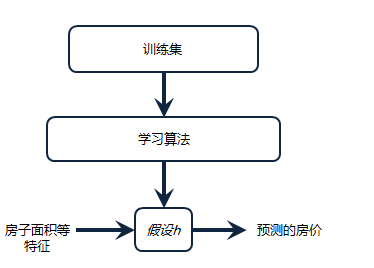
算法模型以简单多变量线性回归为例
| 面积(㎡) | 卧室数 | 卫生间数 | 房龄 | 售价(百万元) |
|---|---|---|---|---|
| 62.47 | 2 | 1 | 12 | 213 |
| 58.05 | 1 | 1 | 20 | 180 |
| 55.87 | 1 | 1 | 16 | 152 |
| 68.04 | 2 | 2 | 18 | 198 |

那么,这里的假设函数
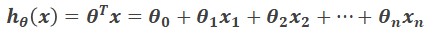
假设值与真实值之间的差就是这个模型的误差(代价)
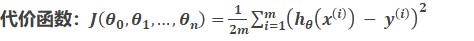
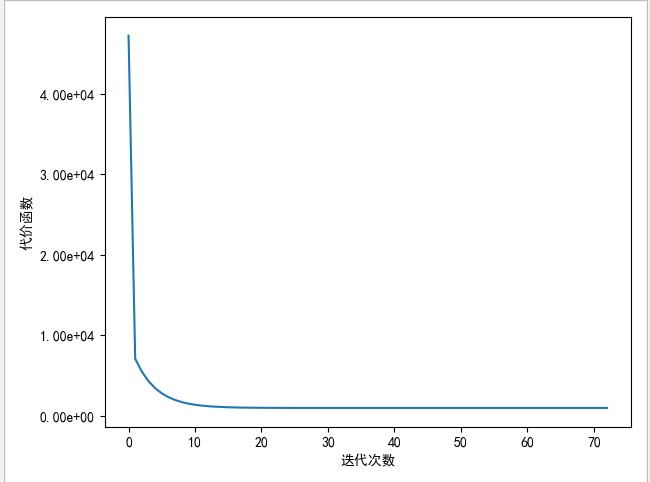
当代价函数的值趋近于0时,模型就比较完美了
参数调整
那怎样能是代价函数最小化?
梯度下降
共轭梯度
拟牛顿迭代法(BFGS)
L-BFGS
......
这里,我们已梯度下降法为例:


模型评估
对于分类问题:
正确率、召回率、F1值等等


对于回归问题:
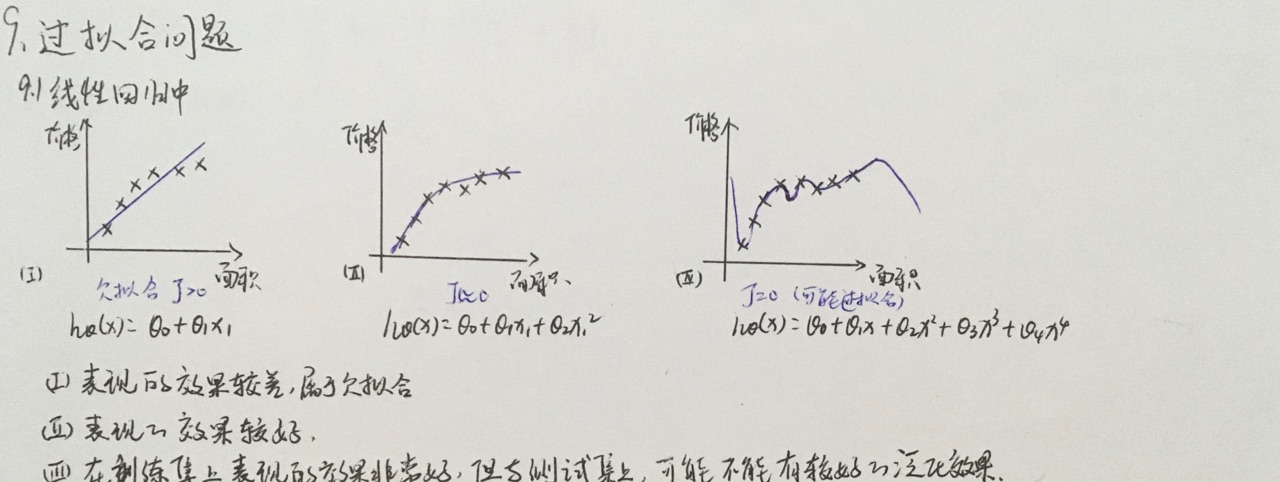

与过拟合对应的,就有欠拟合
实际预测
直接将样本参数带入h假设函数,便可以得到预测值
简单线性回归实现
1 | |