The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
1. 三台linux服务器的安装
1. 安装VmWare Fusion
2.通过Vmware安装三台linux机器
3.为linux虚拟机设置网络配置
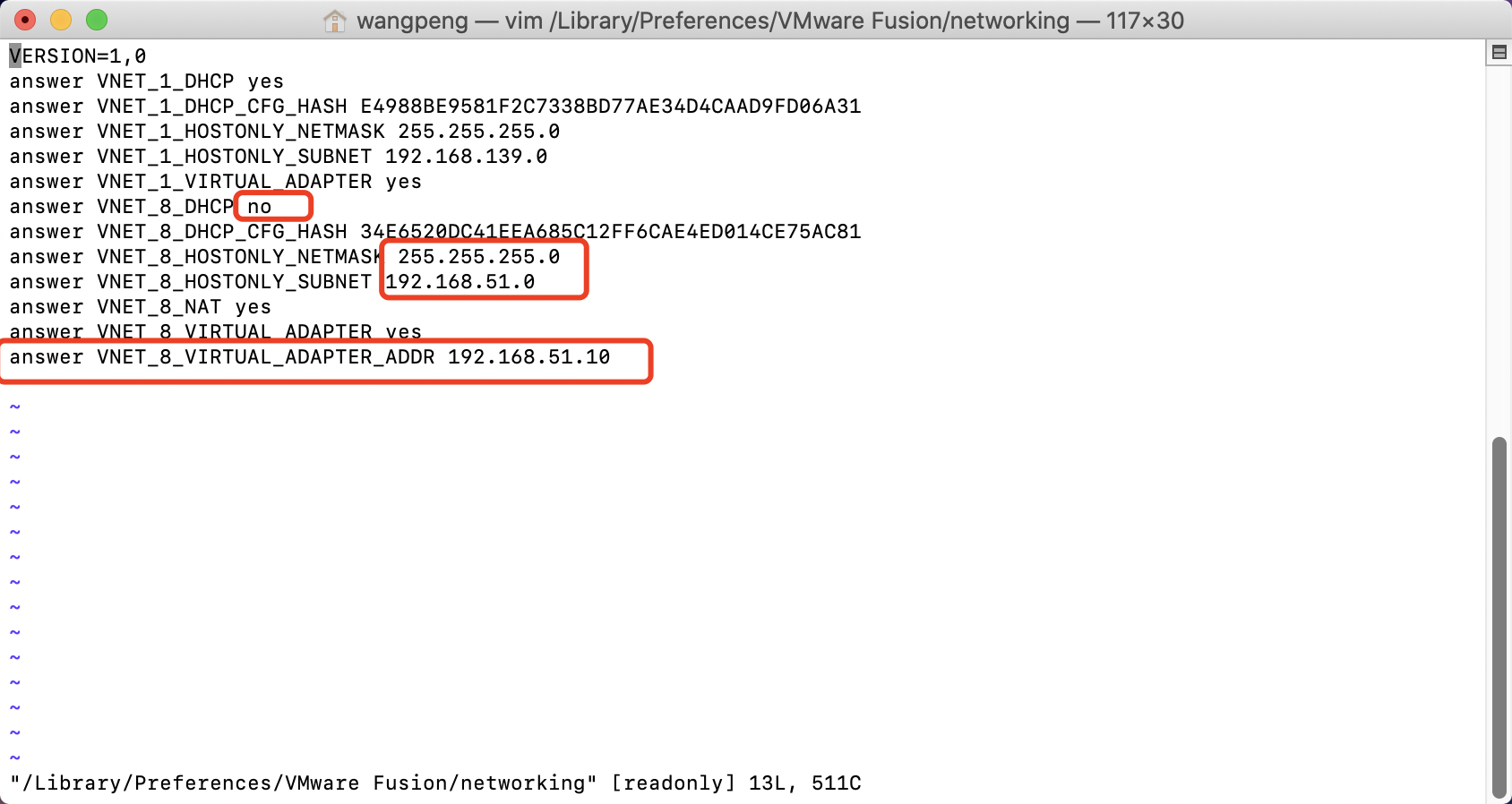
安装VMWare Fusion成功后,Mac OS会新增两张网卡vmnet1以及vmnet8,其中vmnet1是Host-only模式,vmnet8是NAT模式,这里选择vmnet8使用NAT进行网络设置。
1.修改Fusion网络配置
修改配置文件:/Library/Preferences/VMware Fusion/networking
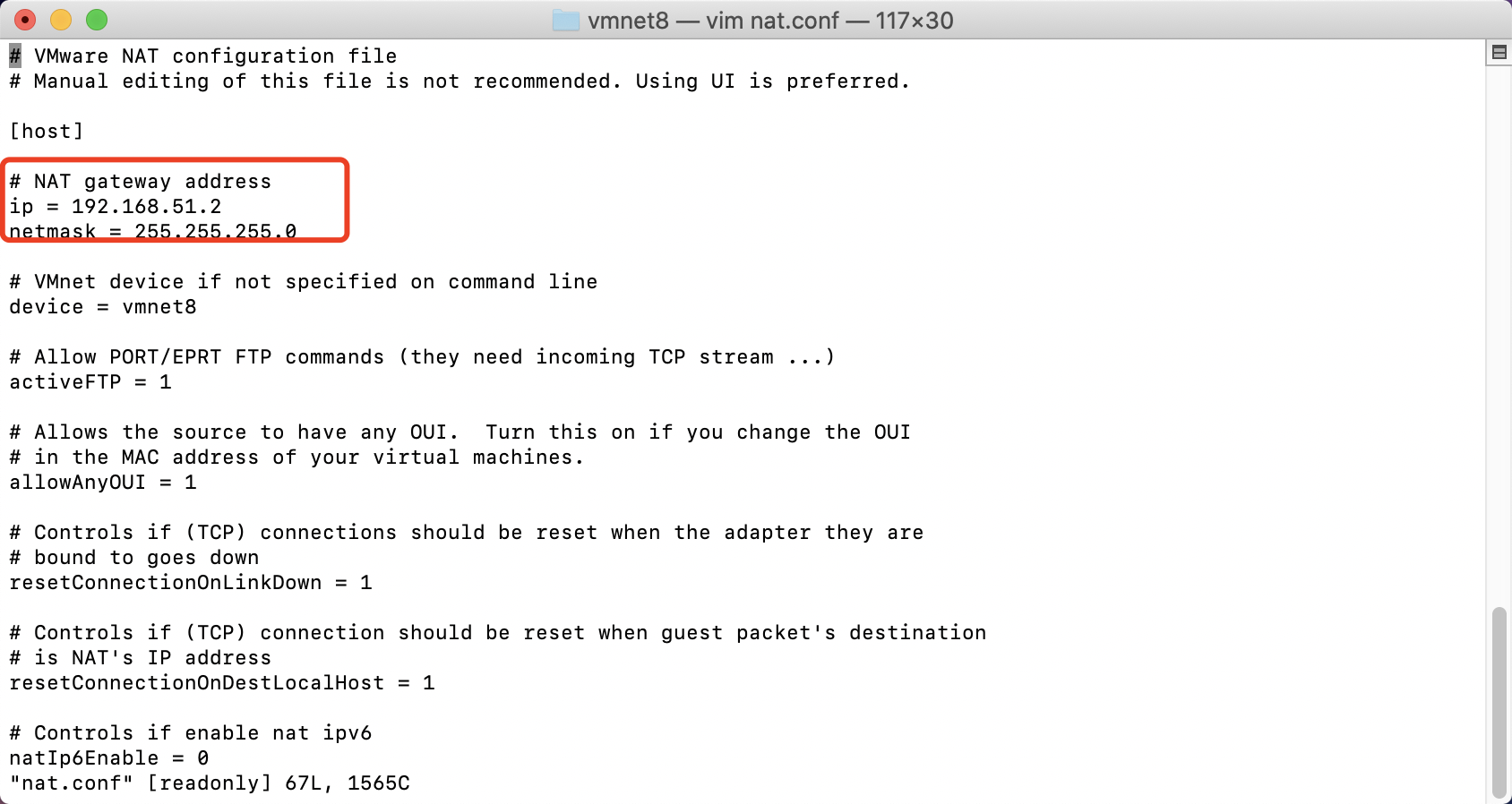
2.修改网关
修改配置文件:/Library/Preferences/VMware Fusion/vmnet8/nat.conf
3.修改linux虚拟机网卡
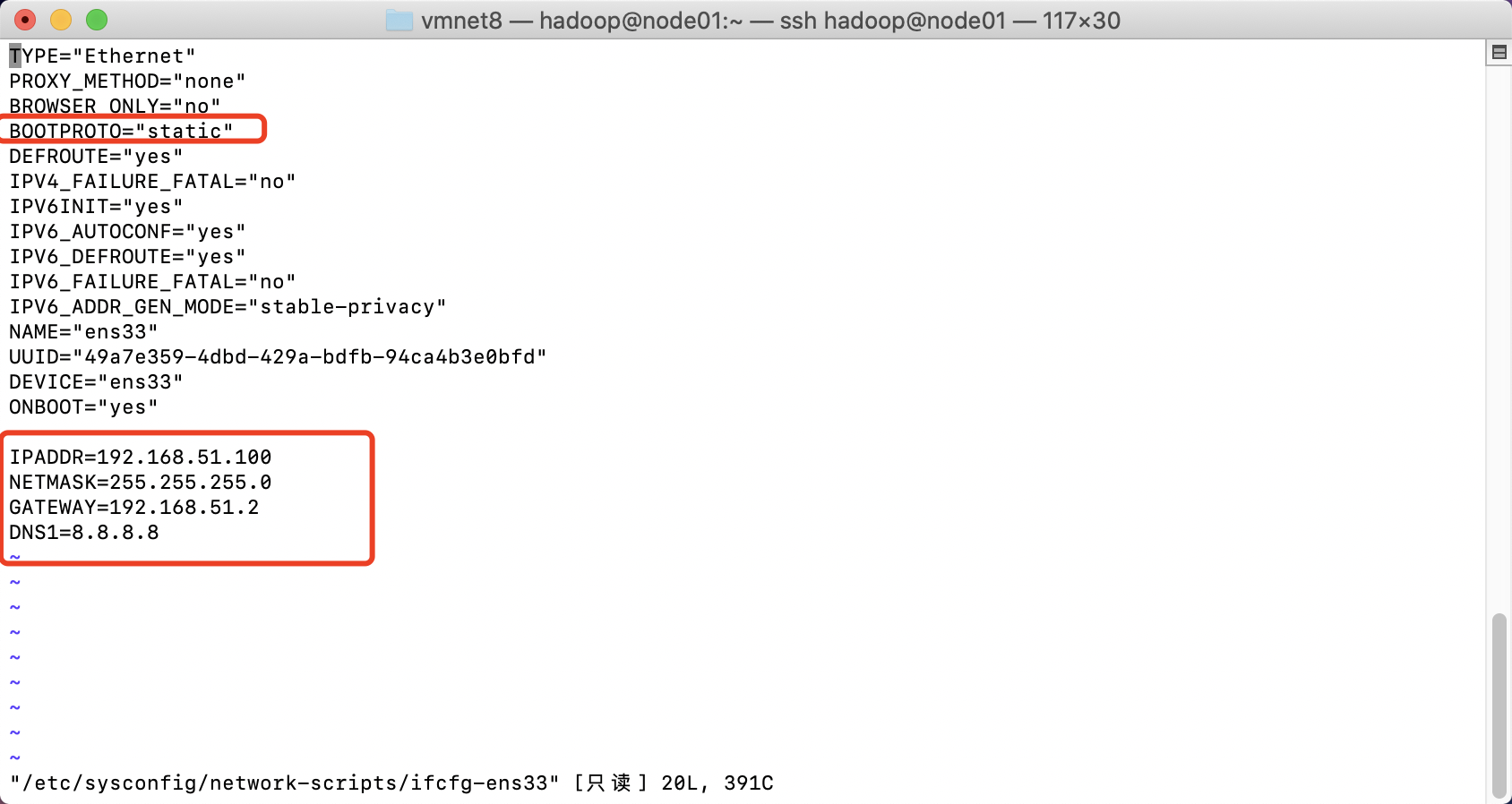
修改配置文件(服务器版linux):/etc/sysconfig/network-scripts/ifcfg-ens33
更改完成配置,重启网络服务
1 systemctl restart network
安装一些常用的软件
1 2 yum -y install vim
关机
4.克隆第一台linux虚拟机
现在已经有了种子机器了,我们可以通过种子机器进行复制或者克隆出三台机器
更改克隆机器的IP地址
三台机器的ip地址分别是192.168.51.100、192.168.51.110、192.168.51.120
克隆出来的机器IP地址与种子的ip地址一样,我们将第二台机器的IP地址更改为192.168.51.110即可
启动虚拟机,并通过root用户,密码******来进行登录,然后来更改linux机器的IP地址
1 vi /etc/sysconfig/network-scripts/ifcfg-ens33
1 2 3 4 IPADDR=192.168.51.110
2.安装大数据集群前环境准备
1. 三台虚拟机关闭防火墙
三台机器执行以下命令(root 用户来执行)
1 2 systemctl stop firewalld
2. 三台机器关闭selinux
三台机器执行以下命令关闭selinux
1 2 vim /etc/sysconfig/selinux
3. 三台机器更改主机名
三台机器执行以下命令更改主机名
第一台机器更改内容
第二台机器更改内容
第三台机器更改内容
4. 三台机器做主机名与IP地址的映射
三台机器执行以下命令更改主机名与IP地址的映射/etc/hosts
1 2 3 192.168.51.100 node01.hadoop.com node01
5. 三台机器时钟同步
第一种同步方式:通过网络进行时钟同步
通过网络连接外网进行时钟同步,必须保证虚拟机连上外网
三台机器都安装ntpdate
阿里云时钟同步服务器
三台机器定时任务
添加如下内容
1 */1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
6. 三台机器添加普通用户
三台linux服务器统一添加普通用户hadoop,并给以sudo权限,用于以后所有的大数据软件的安装
并统一设置普通用户的密码为 ==******==
1 2 useradd hadoop
普通用户的密码设置为******
三台机器为普通用户添加sudo权限
增加如下内容
7. 三台定义统一目录
定义三台linux服务器软件压缩包存放目录,以及解压后安装目录,三台机器执行以下命令,创建两个文件夹,一个用于存放软件压缩包目录,一个用于存放解压后目录
1 2 3 mkdir -p /weitrue/soft # 软件压缩包存放目录
8. 三台机器hadoop用户免密码登录
切换用户为hadoop
第一步:三台机器在hadoop 用户下执行以下命令生成公钥与私钥
执行上述命令之后,按三次Enter键即可生成了
第二步:三台机器在hadoop用户下,执行命令拷贝公钥到node01服务器
第三步:node01服务器将公钥拷贝给node02与node03
node01在hadoop用户下,执行以下命令,将authorized_keys拷贝到node02与node03服务器
1 2 3 cd /home/hadoop/.ssh/
第四步:验证;从任意节点是否能免秘钥登陆其他节点;如node01免密登陆node02
9. 三台机器关机重启
三台机器在hadoop用户下执行以下命令,实现关机重启
10. 三台机器安装jdk
1 2 3 cd /weitrue/soft/
1 2 3 # 添加以下配置内容,配置jdk环境变量
让修改马上生效
3. hadoop集群的安装
注意:这里使用打包好的包“hadoop-2.6.0-cdh5.14.2_after_compile.tar.gz”安装部署集群
编译没有什么技巧,主要跟网络好坏有关
1. CDH软件版本重新进行编译
2. hadoop集群的安装
安装环境服务部署规划
HDFS
NameNode
HDFS
SecondaryNameNode
HDFS
DataNode
DataNode
DataNode
YARN
ResourceManager
YARN
NodeManager
NodeManager
NodeManager
历史日志服务器
JobHistoryServer
第一步:上传压缩包并解压
将我们重新编译之后支持snappy压缩的hadoop包上传到第一台服务器并解压;第一台机器执行以下命令
1 2 cd /weitrue/soft/
第二步:查看hadoop支持的压缩方式以及本地库
第一台机器执行以下命令
1 2 cd /weitrue/install/hadoop-2.6.0-cdh5.14.2
如果出现openssl为false,那么所有机器在线安装openssl即可,执行以下命令,虚拟机联网之后就可以在线进行安装了
1 sudo yum -y install openssl-devel
第三步:修改配置文件
修改hadoop-env.sh
第一台机器执行以下命令
1 2 cd /weitrue/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
1 export JAVA_HOME=/weitrue/install/jdk1.8.0_141
修改core-site.xml
第一台机器执行以下命令
1 2 cd /weitrue/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://node01:8020</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /weitrue/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/tempDatas</value > </property > <property > <name > io.file.buffer.size</name > <value > 4096</value > </property > <property > <name > fs.trash.interval</name > <value > 10080</value > </property > </configuration >
修改hdfs-site.xml
第一台机器执行以下命令
1 2 cd /weitrue/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 <configuration > <property > <name > dfs.namenode.secondary.http-address</name > <value > node01:50090</value > </property > <property > <name > dfs.namenode.http-address</name > <value > node01:50070</value > </property > <property > <name > dfs.namenode.name.dir</name > <value > file:///weitrue/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas</value > </property > <property > <name > dfs.datanode.data.dir</name > <value > file:///weitrue/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/datanodeDatas</value > </property > <property > <name > dfs.namenode.edits.dir</name > <value > file:///weitrue/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits</value > </property > <property > <name > dfs.namenode.checkpoint.dir</name > <value > file:///weitrue/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/snn/name</value > </property > <property > <name > dfs.namenode.checkpoint.edits.dir</name > <value > file:///weitrue/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/snn/edits</value > </property > <property > <name > dfs.replication</name > <value > 3</value > </property > <property > <name > dfs.permissions</name > <value > false</value > </property > <property > <name > dfs.blocksize</name > <value > 134217728</value > </property > </configuration >
修改mapred-site.xml
第一台机器执行以下命令
1 2 3 cd /weitrue/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > <property > <name > mapreduce.job.ubertask.enable</name > <value > true</value > </property > <property > <name > mapreduce.jobhistory.address</name > <value > node01:10020</value > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > node01:19888</value > </property > </configuration >
修改yarn-site.xml
第一台机器执行以下命令
1 2 cd /weitrue/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
1 2 3 4 5 6 7 8 9 10 <configuration > <property > <name > yarn.resourcemanager.hostname</name > <value > node01</value > </property > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > </configuration >
修改slaves文件
第一台机器执行以下命令
1 2 cd /weitrue/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
原内容替换为
第四步:创建文件存放目录
第一台机器执行以下命令
node01机器上面创建以下目录
1 2 3 4 5 6 mkdir -p /weitrue/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/tempDatas
第五步:安装包的分发scp与rsync
在linux当中,用于向远程服务器拷贝文件或者文件夹可以使用scp或者rsync,这两个命令功能类似都是向远程服务器进行拷贝,只不过scp是全量拷贝,rsync可以做到增量拷贝,rsync的效率比scp更高一些
通过scp直接拷贝
scp(secure copy)安全拷贝
可以通过scp进行不同服务器之间的文件或者文件夹的复制
使用语法
1 scp -r sourceFile username@host:destpath
用法示例
1 scp -r hadoop-lzo-0.4.20.jar hadoop@node01:/weitrue/
node01执行以下命令进行拷贝
1 2 3 cd /weitrue/install/
第六步:配置hadoop的环境变量
三台机器都要进行配置hadoop的环境变量
三台机器执行以下命令
1 2 export HADOOP_HOME=/weitrue/install/hadoop-2.6.0-cdh5.14.2
配置完成之后生效
第七步:集群启动
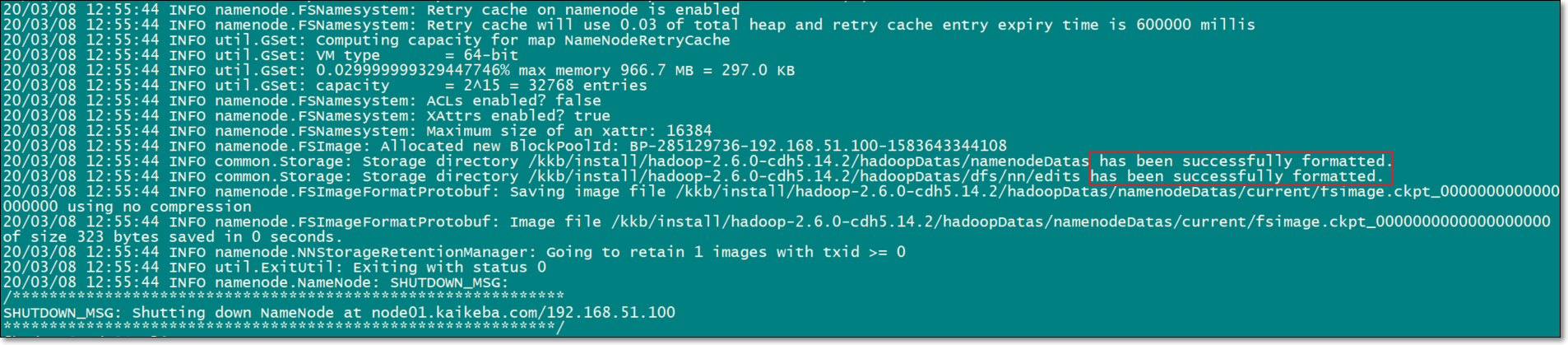
1. 格式化集群
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个集群。
注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的 HDFS 在物理上还是不存在的。格式化操作只有在首次启动的时候需要,以后再也不需要了
node01执行一遍即可
或者
启动集群有两种方式:①脚本一键启动;②单个进程逐个启动
2. 脚本一键启动
如果配置了 etc/hadoop/slaves 和 ssh 免密登录,则可以使用程序脚本启动所有Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
启动集群
node01节点上执行以下命令
第一台机器执行以下命令(hadoop/sbin目录下)
1 2 3 start-dfs.sh
停止集群:
1 2 stop-dfs.sh
3. 单个进程逐个启动
1 2 3 4 5 6 7 8 9 10 11 12 13 在主节点上使用以下命令启动 HDFS NameNode:
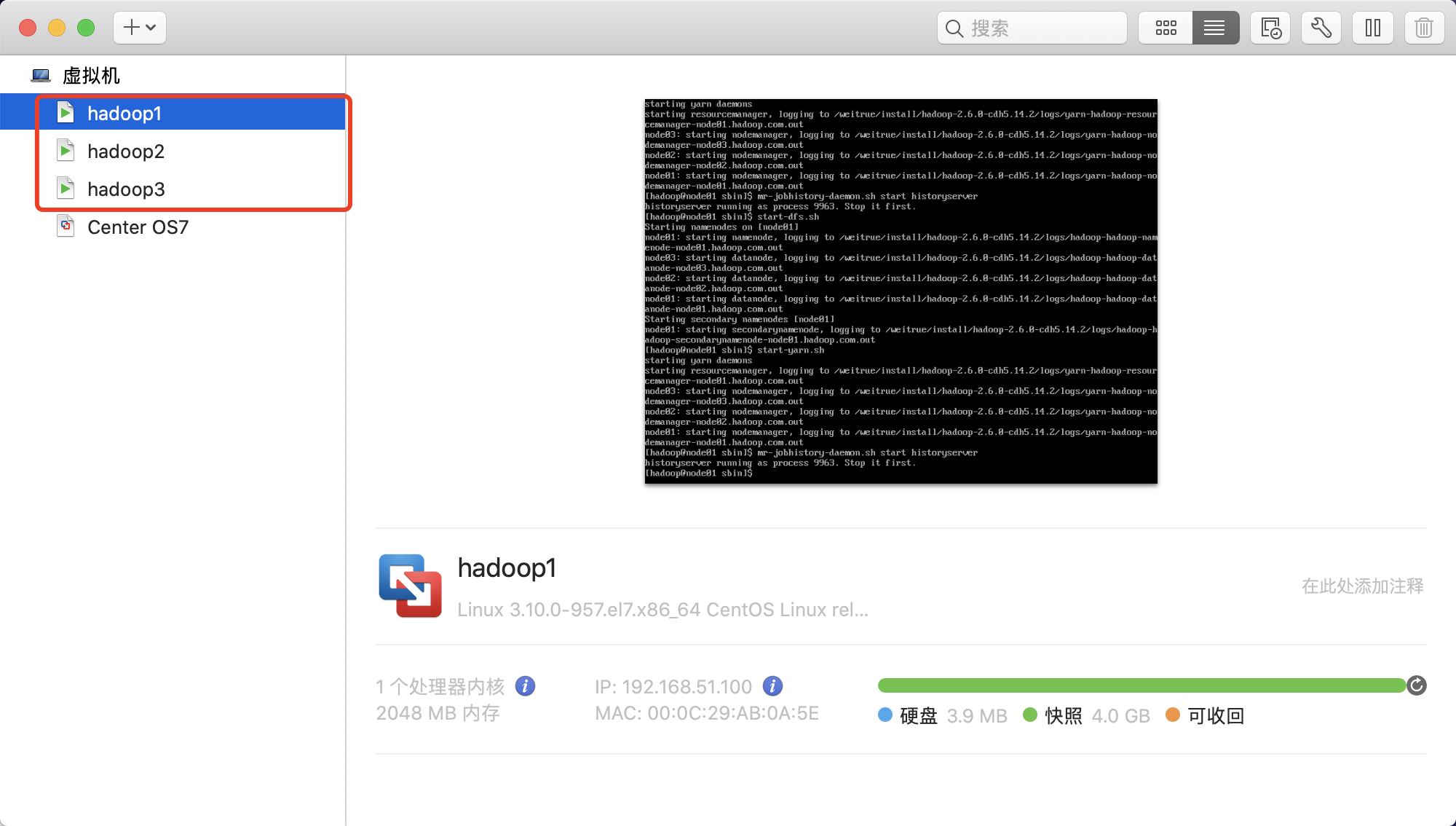
4.一键启动hadoop集群的脚本
我们也可以创建一键启动hadoop的脚本,以后启动hadoop都可以通过一个脚本即可
在node01服务器的/home/hadoop/bin目录下创建脚本
1 2 [hadoop@node01 bin]$ cd /home/hadoop/bin/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # !/bin/bash
修改脚本权限
1 2 3 [hadoop@node01 bin]$ chmod 777 hadoop.sh
第八步:浏览器查看启动页面
hdfs集群访问地址
http://192.168.51.100:50070/
yarn集群访问地址
http://192.168.51.100:8088
jobhistory访问地址:
http://192.168.51.100:19888
==如果要关闭电脑时,清一定要按照以下顺序操作,否则集群可能会出问题==